
Giới thiệu
Gần đây, tôi đã làm việc trong một dự án liên quan đến Cảng thông minh, trong đó một trong những nhiệm vụ là xây dựng dịch vụ nhận dạng số container vận chuyển theo thời gian thực. Nói một cách đơn giản, nhiệm vụ này là nhận diện số container từ hình ảnh của các container vận chuyển. Số container là một chuỗi gồm 11 ký tự bao gồm chữ cái in hoa và số, duy nhất trên toàn thế giới. Nếu bạn chưa quen với số container, có thể bài viết này sẽ hữu ích cho bạn.
Dịch vụ này xử lý hình ảnh của các container và xuất ra số container gồm 11 ký tự và mã kích thước loại ISO gồm 4 ký tự. Bài viết này chủ yếu tập trung vào việc nhận diện số container, vì phương pháp xử lý chúng là giống nhau, còn việc xử lý mã ISO thì đơn giản hơn. Hình dưới đây hiển thị một số ví dụ về nhận dạng số container, với số container được bao quanh bởi hộp màu xanh lá và mã ISO trong hộp màu vàng. Số container đã nhận dạng được hiển thị ở góc trên bên trái. Như bạn có thể thấy, số container có thể xuất hiện ở nhiều vị trí khác nhau trên container, chẳng hạn như cửa, bên hông, trên đầu, v.v.
Ví dụ nhận dạng số container
Độ chính xác và sự ổn định của hệ thống cuối cùng rất cao, với độ chính xác vượt quá 99,5% (trong bộ dữ liệu thử nghiệm của khách hàng). Các mô hình tiên tiến và bộ sưu tập dữ liệu hình ảnh chất lượng cao là những yếu tố quan trọng tạo nên kết quả xuất sắc này. Vì lý do thương mại của dự án, các tham số mô hình và bộ dữ liệu cuối cùng sẽ không được công bố. Không phải mọi chi tiết đều có thể chia sẻ, nhưng tôi sẽ cố gắng chia sẻ càng nhiều ý tưởng và kỹ thuật càng tốt. Các hình ảnh và bộ dữ liệu được sử dụng trong bài viết này được thu thập từ các nguồn công khai trên mạng trong giai đoạn đầu, vì vậy bạn có thể sử dụng chúng một cách tự tin. GIF dưới đây cho thấy hoạt động nhận dạng số container, chỉ dành cho mục đích trình diễn và thử nghiệm.
Demo
Bài viết này là phần đầu tiên trong loạt bài “Xây dựng hệ thống nhận dạng số container vận chuyển mạnh mẽ”. Bạn có thể tìm tất cả các phần tại đây:
- Phần 1: Nhiệm vụ, Thách thức, Thiết kế Hệ thống
- Phần 2: Công cụ, Chú thích hình ảnh, Chuẩn bị dữ liệu
- Phần 3: Huấn luyện, Xây dựng quy trình làm việc, Triển khai, Những điều cần lưu ý
Thách thức
Nhiệm vụ này có thể có vẻ đơn giản (đó là cảm giác của tôi khi lần đầu tiên nghe về dự án này). Tuy nhiên, thực tế nó mang lại nhiều thách thức và chi tiết cần phải xem xét. Hoàn thành dự án này có thể đơn giản, nhưng để đạt được sự xuất sắc là một thử thách. Dưới đây là một số thách thức đáng chú ý:
1.Số Container nhiều hướng
Số container có thể được sắp xếp theo chiều ngang hoặc chiều dọc. Ngoài ra, trong các bức ảnh chụp, chúng không phải lúc nào cũng hoàn toàn ngang hoặc dọc; đôi khi, có một góc nghiêng. Hầu hết các mô hình nhận dạng văn bản hoạt động kém khi nhận dạng văn bản theo chiều dọc, vì vậy cần phải xử lý đặc biệt hoặc huấn luyện riêng biệt với một lượng lớn hình ảnh chứa văn bản dọc.

2.Số Container Hai Dòng
Hình ảnh của container thường được chụp trong môi trường ngoài trời, vì vậy chất lượng hình ảnh có thể kém, ví dụ, do ánh sáng không đều hoặc mờ. Một số ký tự có thể bị che khuất bởi ánh sáng mạnh hoặc bóng đổ. Vào ban đêm, khi chỉ có ánh sáng từ cảng, độ sáng và độ rõ nét của hình ảnh có thể giảm đáng kể. Những yếu tố này có thể dẫn đến hiệu suất nhận dạng mô hình kém. Đây là một thách thức phổ biến đối với hầu hết các nhiệm vụ thị giác máy tính. May mắn thay, một bộ dữ liệu chất lượng cao, bao gồm nhiều điều kiện khác nhau, có thể giảm thiểu vấn đề này.

1. Số Container với Ánh Sáng Khác Nhau
Container thường được đặt trong môi trường ngoài trời, nơi các ký tự có thể bị che khuất bởi vết bẩn, xước, rỉ sét, v.v. Những yếu tố này có thể dễ dàng gây ra lỗi, vì ngay cả con người cũng có thể gặp khó khăn trong việc nhận diện trong một số tình huống nhất định. Đối với những trường hợp này, cần phải thực hiện việc sửa chữa ký tự (sử dụng kiểm tra chữ số kiểm tra của số container và kinh nghiệm thực tế) hoặc kiểm tra chéo với dữ liệu cảng hiện có, chẳng hạn như thông tin về sự đến của container.

1.Số Container Mòn và Hư Hỏng
Hệ thống nhận dạng cần được vận hành theo thời gian thực, vì vậy cần phải cân bằng giữa tốc độ và độ chính xác. Đây là một vấn đề điển hình của sự đánh đổi giữa tốc độ và độ chính xác. Chúng ta cần tối đa hóa tốc độ nhận dạng trong khi đảm bảo độ chính xác. Hơn nữa, thiết kế dư thừa của hệ thống phải đủ mạnh mẽ để đảm bảo sự ổn định, đặc biệt là khả năng phục hồi thảm họa, vì các hoạt động cảng diễn ra liên tục suốt 24 giờ mỗi ngày. Hệ thống nhận dạng này được triển khai cục bộ dưới dạng Docker, cung cấp dịch vụ API. Phần này không phải là trọng tâm của bài viết, vì nó đi vào một chủ đề hoàn toàn khác.

1.Tính realtime
Hệ thống nhận dạng cần được vận hành theo thời gian thực, vì vậy cần phải cân bằng giữa tốc độ và độ chính xác. Đây là một vấn đề điển hình của sự đánh đổi giữa tốc độ và độ chính xác. Chúng ta cần tối đa hóa tốc độ nhận dạng trong khi đảm bảo độ chính xác. Hơn nữa, thiết kế dư thừa của hệ thống phải đủ mạnh mẽ để đảm bảo sự ổn định, đặc biệt là khả năng phục hồi thảm họa, vì các hoạt động cảng diễn ra liên tục suốt 24 giờ mỗi ngày. Hệ thống nhận dạng này được triển khai cục bộ dưới dạng Docker, cung cấp dịch vụ API. Phần này không phải là trọng tâm của bài viết, vì nó đi vào một chủ đề hoàn toàn khác.
Thiết kế quy trình nhận dạng
Sơ đồ dưới đây minh họa sơ bộ quy trình làm việc đơn giản của hệ thống nhận dạng. CN đại diện cho Số Container, và TS đại diện cho mã kích thước loại ISO (ví dụ: 45G1, 22G1, v.v.). Hình minh họa chỉ thể hiện quy trình nhận dạng số container, còn quy trình nhận dạng mã kích thước loại ISO tương tự.
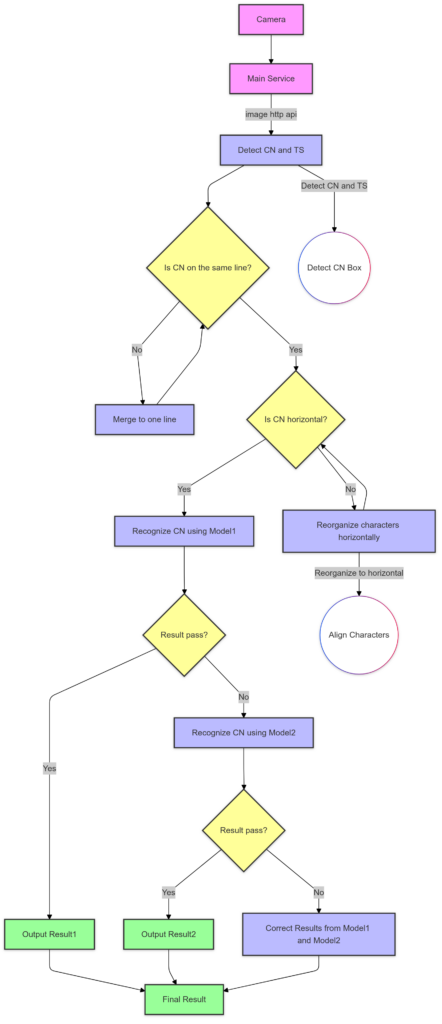
Dưới đây là một số điểm chính của quy trình nhận dạng:
Tiền xử lý hình ảnh: Dựa trên kinh nghiệm xử lý hình ảnh truyền thống, việc thực hiện một số bước tiền xử lý, chẳng hạn như giảm nhiễu và cải thiện độ tương phản, có thể cải thiện hiệu suất tổng thể của hệ thống. Tuy nhiên, trong dự án này, theo kết quả thử nghiệm thực tế, các thao tác tiền xử lý này là không cần thiết và không cải thiện hiệu suất cuối cùng của hệ thống. Các mô hình phát hiện và nhận dạng được huấn luyện với một lượng lớn dữ liệu chất lượng cao có độ bền vững mạnh mẽ và có thể xử lý được một mức độ nhiễu và ánh sáng không đều. Thực tế, đây là một trong những ưu điểm của các mô hình học máy, hiện tượng tương tự cũng được quan sát thấy trong các nhiệm vụ xử lý hình ảnh khác sử dụng các mô hình học máy. Thao tác tiền xử lý duy nhất có thể cần thiết là thay đổi kích thước hình ảnh. Hệ thống không yêu cầu hình ảnh đầu vào ở kích thước ban đầu lớn của chúng để đạt được kết quả nhận dạng tốt, vì vậy hình ảnh có thể được thay đổi kích thước xuống một kích thước phù hợp để giảm tải tính toán.
Phát hiện số container: Đây là bước đầu tiên trong quy trình nhận dạng. Mô hình phát hiện này có nhiệm vụ xác định vị trí của số container (và mã kích thước loại ISO…) trong hình ảnh. Mô hình này được huấn luyện bằng thuật toán phát hiện YOLOv8. Nó xuất ra tọa độ của số container trong hình ảnh, và các tọa độ này được sử dụng để cắt các vùng số container từ hình ảnh gốc.
Tổ chức lại vùng số container:
- Gộp thành một dòng: Vì một số số container có thể được phân bố trên hai dòng, nên cần phải gộp các vùng số trên nhiều dòng này thành một dòng hoặc cột duy nhất. Việc đơn giản hóa này giúp cho quá trình nhận dạng sau này và có thể tăng độ chính xác. Để gộp chính xác các vùng, việc phát hiện chính xác liệu một dòng có thuộc phần của số container hay không là rất quan trọng. Liệu nó có liên quan đến phần số container hay không là một vấn đề mà mô hình phát hiện ở bước đầu cần phải giải quyết. Các chi tiết cụ thể sẽ được giới thiệu trong bài viết sau.

Gộp số container thành một dòng
- Sắp xếp lại theo chiều ngang: Nếu số container được sắp xếp theo chiều dọc, nó cần phải được sắp xếp lại theo chiều ngang, vì tôi muốn hệ thống chỉ nhận dạng văn bản theo chiều ngang, vì hầu hết các mô hình OCR hoạt động kém với văn bản sắp xếp theo chiều dọc. Ở đây, việc sắp xếp lại theo chiều ngang không đơn giản như xoay hình ảnh 90 hoặc 270 độ, vì việc xoay như vậy sẽ làm các ký tự trong hình ảnh không đứng thẳng. Mặc dù các mô hình OCR có thể nhận dạng văn bản xoay, nhưng xét về hiệu suất nhận dạng và sự tiện lợi trong việc xử lý sau này, văn bản sắp xếp theo chiều ngang với các ký tự đứng thẳng là sự lựa chọn tốt nhất. Hình dưới đây minh họa quá trình sắp xếp lại. Trong quá trình này, một mô hình phát hiện ký tự mới được huấn luyện để phát hiện các ký tự riêng lẻ (cũng sử dụng phát hiện YOLOv8), sau đó hệ thống sắp xếp lại các ký tự đã phát hiện theo thứ tự ngang.
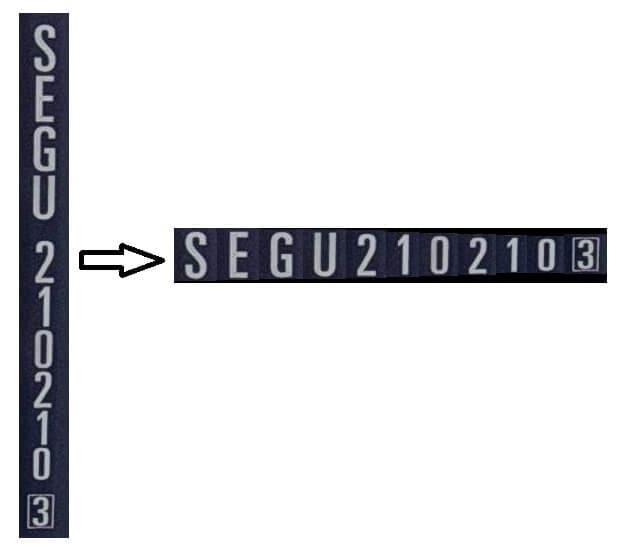
Sắp xếp lại số container
Nhận dạng số container: Một khi hình ảnh cắt của số container theo chiều ngang đã sẵn sàng, nó có thể được nhận dạng bằng mô hình nhận dạng văn bản. Ở đây, PaddleOCR được sử dụng để huấn luyện mô hình nhận dạng văn bản, bao gồm nhiều thuật toán nhận dạng văn bản phổ biến; các chi tiết sẽ được giải thích trong bài viết sau. Đáng chú ý là hệ thống của chúng tôi sử dụng hai mô hình thuật toán nhận dạng khác nhau để nhận diện số container. Nếu kết quả từ mô hình nhận dạng đầu tiên không thành công qua kiểm tra, hệ thống sẽ sử dụng mô hình nhận dạng thứ hai để làm lại. Nếu mô hình thứ hai cũng thất bại, hệ thống sẽ so sánh và sửa chữa hai kết quả để xuất ra kết quả cuối cùng. Trong ứng dụng thực tế, việc sử dụng nhiều mô hình để cải thiện độ chính xác là một thực tiễn phổ biến. Dĩ nhiên, điều này không thể tránh khỏi việc tăng thời gian xử lý, nhưng may mắn thay, sự tăng này là chấp nhận được trong hệ thống tổng thể.
Lưu ý: Trong hệ thống nhận dạng, tính chính xác của kết quả nhận dạng có thể được kiểm tra thông qua tính toán chữ số kiểm tra của số container. Ký tự cuối cùng của số container là một chữ số kiểm tra, được tính toán dựa trên mười ký tự trước đó. Để biết các quy tắc tính toán chữ số kiểm tra, bạn có thể tham khảo bài viết này.
Dưới đây là hàm Python tính toán chữ số kiểm tra:
# Tính toán chữ số kiểm tra (check-digit) của mã container
# Input: container_code - 10 ký tự đầu tiên của mã container
# Output: check_digit - ký tự thứ 11 của mã container
def calculate_check_digit(container_code):
# Bước 1: Ánh xạ các chữ cái từ A-Z sang các giá trị số tương ứng
# Theo quy chuẩn quốc tế, mỗi chữ cái được gán một giá trị số cố định
letter_values = {
'A': 10, 'B': 12, 'C': 13, 'D': 14, 'E': 15, 'F': 16, 'G': 17, 'H': 18, 'I': 19, 'J': 20,
'K': 21, 'L': 23, 'M': 24, 'N': 25, 'O': 26, 'P': 27, 'Q': 28, 'R': 29, 'S': 30, 'T': 31,
'U': 32, 'V': 34, 'W': 35, 'X': 36, 'Y': 37, 'Z': 38
}
# Bước 2: Chuyển đổi từng ký tự trong mã container thành giá trị tương ứng
values = []
for char in container_code:
if char.isalpha(): # Nếu ký tự là chữ cái
values.append(letter_values[char]) # Lấy giá trị từ letter_values
else: # Nếu ký tự là chữ số
values.append(int(char)) # Chuyển trực tiếp thành số nguyên
# Bước 3: Tính tổng trọng số các giá trị
# Nhân mỗi giá trị với 2^(vị trí-1), với vị trí bắt đầu từ 0
total = sum(val * (2 ** i) for i, val in enumerate(values))
# Bước 4: Tính chữ số kiểm tra (check digit)
# Chữ số kiểm tra là phần dư của tổng khi chia cho 11
check_digit = total % 11
# Nếu phần dư là 10, chữ số kiểm tra sẽ được đặt là 0
if check_digit == 10:
check_digit = 0
# Trả về chữ số kiểm tra
return check_digit
# Ví dụ sử dụng hàm:
container_code = "ABC1234567" # 10 ký tự đầu tiên của mã container
check_digit = calculate_check_digit(container_code) # Tính chữ số kiểm tra
print(f"Check digit for container code {container_code} is {check_digit}")Giải thích từng bước:
- Ánh xạ chữ cái sang giá trị số:
Các chữ cái từA-Zđược ánh xạ sang các giá trị cố định. Ví dụ,Atương ứng với10,Bvới12, v.v. Điều này dựa trên quy chuẩn mã hóa của ngành vận tải. - Chuyển đổi mã container:
- Nếu ký tự là chữ cái (
isalpha()), tìm giá trị tương ứng trong từ điểnletter_values. - Nếu ký tự là số, chuyển trực tiếp sang số nguyên bằng
int().
- Nếu ký tự là chữ cái (
- Tính tổng trọng số:
- Với mỗi giá trị, nhân nó với
2^(vị trí-1). Vị trí (i) bắt đầu từ 0. Đây là công thức chuẩn để tính chữ số kiểm tra.
- Với mỗi giá trị, nhân nó với
- Tính chữ số kiểm tra:
- Chia tổng cho 11 và lấy phần dư (
% 11). - Nếu phần dư là
10, chữ số kiểm tra được gán là0.
- Chia tổng cho 11 và lấy phần dư (
- Ví dụ kết quả:
Nếucontainer_code = "ABC1234567", các giá trị chuyển đổi là:A = 10,B = 12,C = 13,1 = 1,2 = 2,3 = 3,4 = 4,5 = 5,6 = 6,7 = 7.- Tổng trọng số là:
10*1 + 12*2 + 13*4 + 1*8 + 2*16 + 3*32 + 4*64 + 5*128 + 6*256 + 7*512 = 4067. - Chữ số kiểm tra là
4067 % 11 = 10, nhưng vì10không hợp lệ, nó được thay bằng0.
Kết quả:
Hàm trả về check_digit = 0 cho mã ABC1234567.
Tổng kết
Trong bài viết này, chúng ta đã khám phá các thách thức và thiết kế hệ thống nhận diện số container từ ảnh sử dụng kỹ thuật học máy tiên tiến. Quá trình nhận diện bao gồm nhiều bước quan trọng như tiền xử lý ảnh, phát hiện và nhận diện số container, cùng với việc xử lý các tình huống khó khăn như ánh sáng không đồng đều, vết bẩn, hay số container bị mờ hoặc bị che khuất. Đặc biệt, chúng ta đã xem xét cách hệ thống nhận diện số container trong môi trường thực tế, nơi yêu cầu về tốc độ và độ chính xác luôn phải được cân bằng.
Hệ thống của chúng tôi đạt được độ chính xác cao, với khả năng xử lý nhanh chóng ngay cả trong các điều kiện phức tạp. Như đã đề cập, chúng tôi sử dụng các mô hình học máy để cải thiện khả năng nhận diện và giảm thiểu lỗi. Mặc dù không chia sẻ chi tiết về mô hình và bộ dữ liệu, nhưng các phương pháp chung mà chúng tôi trình bày có thể áp dụng cho nhiều bài toán nhận diện văn bản trong các tình huống tương tự.
Trong bài viết tiếp theo, chúng ta sẽ đi sâu vào công cụ và phương pháp chuẩn bị dữ liệu, bao gồm cách đánh dấu ảnh và chuẩn bị bộ dữ liệu chất lượng cao để huấn luyện mô hình nhận diện. Hẹn gặp lại bạn ở phần tiếp theo của loạt bài viết về xây dựng hệ thống nhận diện số container này!